Data science is often depicted as a field that lies at the intersection of computer science, mathematics/statistics, and domain-specific expertise. Why is domain knowledge important in data science? In this blog post, we will show the value of domain knowledge in data analysis from multiple perspectives.
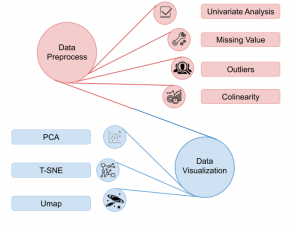
As shown in Figure 1, a data analysis project can be decomposed into different steps, including problem formulation, data collection, data preprocessing, modeling, and result interpretation. We will start with some simple case studies to demonstrate how domain knowledge can help us with every stage of the data analysis workflow. Then we will use a few examples to provide an in-depth exploration of the role of domain knowledge in data science. Finally, we conclude with a discussion of different viewpoints on the importance of domain knowledge and a “takeaways” diagram which we hope will help the readers in future data analysis projects.
Precise and accurate problem definition is critical for the overall success of a data analysis project. Domain knowledge can often help us reach this precision and accuracy. For example, if we want to build a recommender system for an e-commerce platform, we need to understand how users browse online-stores. Without domain knowledge, we might simply define our objective as “building a good recommender system that increases net revenue” which lacks precision. However, a domain expert might articulate that when evaluating our recommendation systems, we need to correctly identify the increased user interest generated by recommendations. Thus it may be better to focus on the website CTR (click-through rate), because aside from the recommendations, there can be other reasons behind the revenue lift, such as recent Holiday Sales events (Mukherjee, 2019).
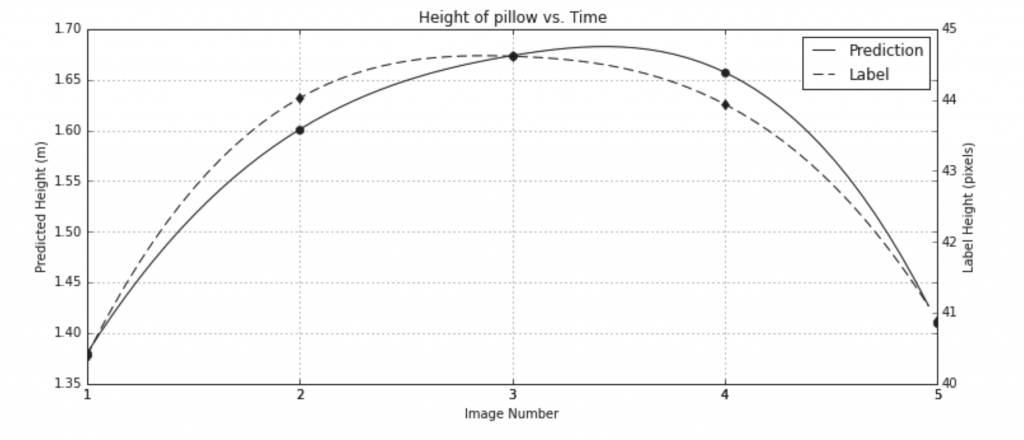
If we have proper domain insights, we may reduce the burden of data collection and/or collect data with better quality. For example, prior work suggests that neural networks can be trained on algebraic and logical relationships that are known to hold without labeling (Stewart & Ermon, 2017). In this work, the researchers aim to train a regression neural network to predict the height of a free-falling object given a sequence of video frames. Rather than training the model on direct labels, the authors supervised the network using the physics of free-falling objects. Because objects under gravity have a fixed acceleration as shown in Equation (1), according to Newton’s Law, we can derive the formula of the height of a free-falling object over time as a parabola in Equation (2).
This formula derived from domain knowledge in physics is then used as the target in this experiment to train the neural network. The computed labels and model predictions are shown in Figure 2. The authors also provide a comparison between the model trained on physical laws and another model trained on manual labels. The evaluation metric is the correlation between predicted object heights and the ground truth pixel measurements. With minimum human labeling labor, the model trained with the physics formula achieves a correlation of 90.1%, which is close to the 94.5% correlation of the model trained on the ground truth.
Another prime example is using domain knowledge to effectively collect data for problems in healthcare. The expertise is critical when we want to build a model to predict a health outcome (for example, whether a patient has or is likely to develop gastrointestinal bleeding) since we need to know which variables might be related to the outcome so we can make sure to gather the right data (Blanchard et al., 2017).
Next, it is crucial to understand our data within the context of the problem we are trying to solve before we move on to modeling. Domain knowledge can help us understand how our data are collected and hence, the appropriate methods for preprocessing. With domain knowledge, we will also have guidance on what features might be helpful to our model. Suppose we want to build a regression model to predict a country’s GDP (gross domestic product) from various economics quantities. An immediate issue we face is determining which features we want to include in our model. Some basic quantities such as “total exports goods and services” and “total imports goods and services” may give us a relatively good model. Yet, with a deeper understanding of the underlying economics, we may want to calculate higher-level features such as “trade openness” and “domestic demand per GDP (without construction)” using the following formula:
These features may have more predictive power in the GDP prediction (Anand et al., 2019).
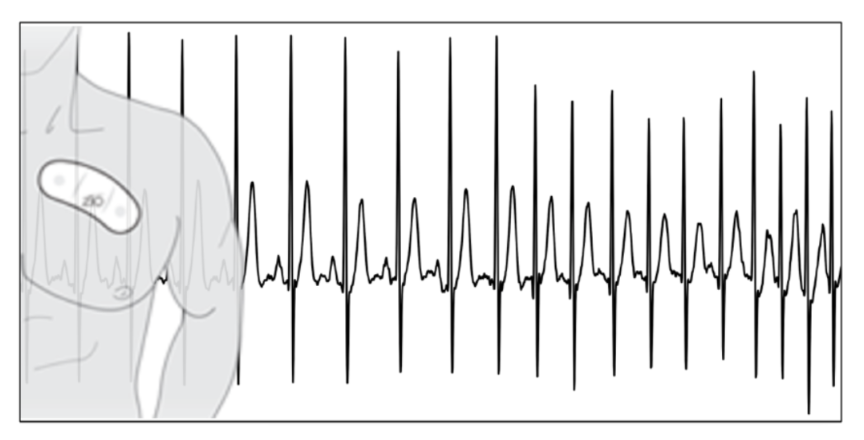
While model selection and evaluation are normally considered technical problems best suited for data scientists, domain knowledge can be indispensable at this step as well. Taking the electrocardiogram (ECG) as an example: people tend to study the sequential nature of an ECG (Figure 3) by using recurrent neural networks (RNN) or other time series models. However, people with clinical background might recommend using a convolutional neural network (CNN) instead since doctors care more about the local patterns in an ECG which often contains more information than long-term repeated patterns. Thus, it may be better to use similar models as those used in image classification that focus more on the local patterns (Rajpurkar et al., 2017).
Domain knowledge may also be needed in the model evaluation stage. A simple example is a need for the subjective evaluation from an expert when evaluating the creativity of a music generation model.
Last but not least, domain knowledge is also very helpful for us to gain insights about the model performance. In a healthcare data project, domain knowledge is often required during the result presentation and communication. We need to know whether the results are important or trivial. Significant coefficients do not necessarily mean the results are important. For example, a strong correlation between age and mortality is not surprising to clinicians. Moreover, we often give preference to actionable results, and so we must consider issues of practicality, which are very domain-dependent. This is again evident in examples from clinical study examples: even if the model indicates medicine A has a positive effect on disease B’s treatment, only clinicians can weigh the benefits against the side effects to determine whether the treatment is justified.
In this part, we will go through a case study to see how domain knowledge helps in medical image analysis (Kyono et al., 2019). Mammography is an X-ray imaging technique for breast cancer prevention and diagnosis. The goal of the project is to develop a model that predicts a diagnosis from the mammogram image.
If you are familiar with computer vision, the problem is a typical image classification problem where the two class labels are malignant/benign (normal). We can use a variety of off-the-shelf CNN image classifiers like VGG, Resnet or Inception to solve this classification problem. Even with little domain knowledge, we can design a reasonable baseline model. However, the authors of the paper dove deeper into this problem and showed how domain knowledge can inspire a model with higher accuracy and better human-machine interaction.
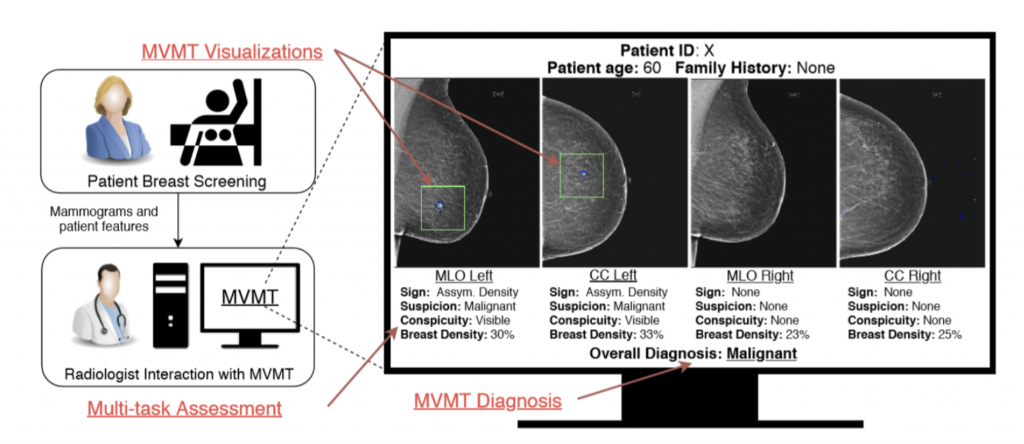
The authors found the radiologists make assessments of some features (conspicuity, suspicion, breast density, etc.) along with diagnosis when they read mammograms. These features are known to be correlated with a cancer diagnosis. For example, the asymmetry of breast densities between the two breasts is an indicator of cancer.
With this domain knowledge, the authors proposed a multi-view multi-task (MVMT) system to more closely mirror the radiologists’ workflow for mammogram diagnosis. Consequently, they developed a multi-task CNN that predicts the diagnosis and 5 auxiliary targets: sign, suspicion, conspicuity, age, and breast density for each mammogram view. A multi-layer perceptron then combines these radiological features to predict the final diagnosis.
The proposed MVMT system achieved better accuracy on both single image diagnosis and multi-view diagnosis. The area under the ROC curve of multi-view diagnosis using the proposed method is 0.855, 0.018 higher than the baseline without multi-task features. The system also has better interpretability since it follows the radiologist’s workflow. In fact, the system generates a radiological assessment report for each mammogram view to help a human better understand how the model arrived at the diagnosis.
In this example, the domain knowledge helps in (i) understanding the data with multiple views, (ii) providing a refined set of features to improve accuracy, and (iii) improving model interpretability and interaction with humans. The domain knowledge also plays an important role in the data preprocessing step to convert the DICOM (Digital Imaging and Communication in Medicine) mammograms into grayscale images. This will require using the right toolkit to access the mammograms and applying the proper transformations to the images.
Making robots capable of completing tasks in the real world is the holy grail of robotics research. Although training robots is not part of the canonical data analysis pipeline, as it requires interaction with the environment, domain knowledge brings great insights towards achieving this goal nonetheless.
It is often not possible to train algorithms directly in the real world due to ethical and logistical issues. Therefore, researchers often train and test algorithms in a simulated environment, before migrating to real-world scenarios (this process is often called sim2real).
However, simulations are never perfect and will require trade-offs. The overall quality of simulation is obviously important for our algorithms to perform well in reality, but we don’t want to overcomplicate our simulation with unnecessary details. So, the billion-dollar question is, what should we include in our simulation? Some aspects of the answer are obvious: goals, metrics, sensor inputs, and the action space are all things that need to be aligned with reality. Are those all we need to consider?
This is where domain knowledge comes to the rescue. It turns out that there is another important aspect that may not be obvious: the effect of actuator noise. Simply put, actuator noise means imperfect movement/action for real-world robots. The work by Jakobi and colleagues shows that actuator noise is a significant factor that should be included in simulations (Jakobi et al., 1995). The two quotes below summarize the main point of the paper:
“In general, networks evolved in an environment that is less noisy than the real world will behave more noisily in real world, conversely, networks evolved in an environment that is noisier than the real world will behave less noisily.”
“If the noise levels used in the simulation differ significantly from those present in reality, whole different classes of behaviours become available which, while acquiring high fitness scores in simulation, fail to work in reality.”
The first quote states the necessity of actuation noise simulation whereas the second quote emphasizes that the level of actuation noise has to be right. Figure 5 illustrates the second point: two robots with different hardware setups will result in different levels of actuation noise in reality.
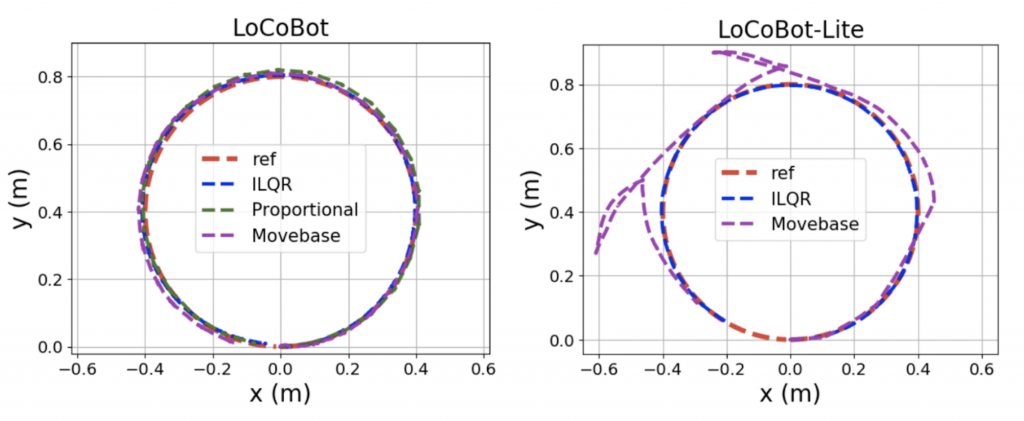
Jakobi et al. configured three virtual robots, with 0%, 100% and 200% of their real noise level respectively, and evaluated the behavior of robots both in simulations and in reality. They used human expert judges to evaluate and defined two metrics, behavioral score, and correspondence score. The former measures robots’ performance in simulation, whereas the latter measures how well the robots transition from simulations to reality. Their experimental results indicate that simulated robots with noise levels equal to their real-world noise level perform the best, both in noisy simulation and in the real world. Given this domain knowledge, we know that simulation environments need to account for actuator noise as well as other sources of variation in order to transfer successfully to the real world.
With all of the positive examples listed above, we would like to introduce one counter-example: AlphaGo Zero. Before AlphaGo Zero, Google Deepmind’s AlphaGo was able to defeat World Go Champion Lee Sedol. However, the training of AlphaGo heavily relied on human experts to evaluate game states. In contrast, AlphaGo Zero is solely trained by reinforcement learning and Monte Carlo Tree Search and has defeated the previous version of AlphaGo in a 100-0 victory. In other words, a model trained from scratch without domain knowledge handily beat the model that utilized domain knowledge. This raises the question: is domain knowledge always beneficial?
In their article published in Nature, Google’s scientists brought up a couple of points that are relevant to our discussion (Silver et al, 2017). The first point is that AlphaGo Zero, in the self-play training phase, was able to come up with human expert moves, such as common corner sequences, life-and-death, shape, etc. A large portion of this knowledge was part of the training data of the previous AlphaGo. However, AlphaGo Zero was perfectly capable of “coming up” with such moves on its own, effectively becoming a “domain expert” throughout the training process. In other words, AlphaGo Zero, similar to human players learning the game, only knew the rules of the game.
Bringing up this example is quite relevant to our discussion about whether domain knowledge is indispensable to the training of machine learning algorithms. It is indisputable that AlphaGo Zero doesn’t require the expertise of expert Go players. However, we argue that it is due to the fact that the rules of Go are well-defined and the environment is deterministic. In real-world applications, this is rarely the case. In most real-world scenarios, rules and boundaries are ambiguous and data comes with a lot of noise. When dealing with a large, intricate system, it is nearly impossible to come up with a successful algorithm without knowing how the system works and how different parts relate to each other. Apart from large-scale systems, some domains like music generation naturally require domain knowledge as raw material. In some other cases, when we are working in a high-stakes field such as healthcare, making decisions based on an algorithm alone is insufficient and can have severe consequences.
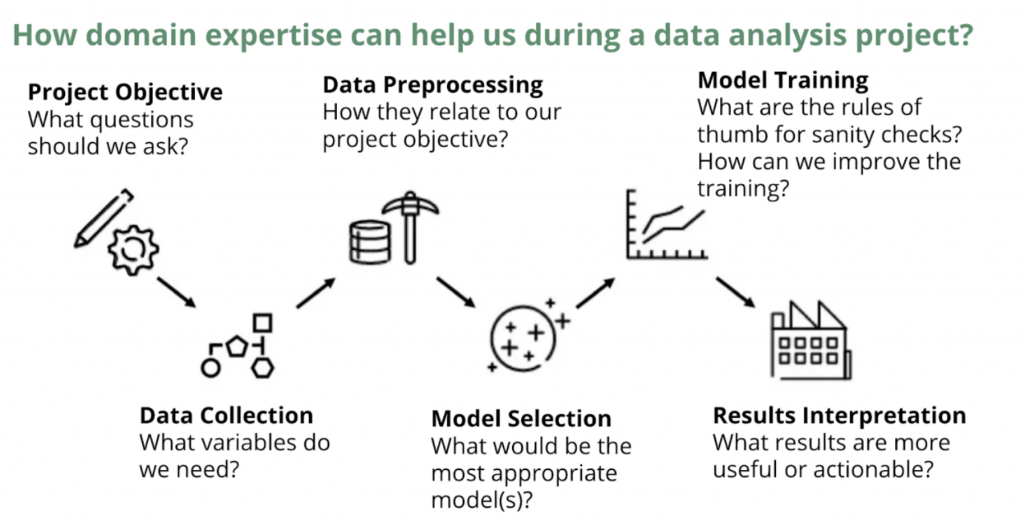
We hope the above case studies convince you that domain knowledge is important for most data analysis projects from problem definition to results interpretation. However, there are limited ways to access domain knowledge. The most common ways to gain access to domain expertise is to 1) read related literature and attend presentations/formal classes and/or 2) establish good relationships and collaborate with domain experts. Once you have access to domain knowledge, ask yourself (or domain experts) the questions in Figure 6 during each step of your data analysis projects. Ideally, this will help you to better understand and interpret your data, objectives, and results.
Mukherjee, A. (2019, April 15). Minimum viable domain knowledge in data science. Retrieved from https://towardsdatascience.com/minimum-viable-domain-knowledge-in-data-science-5be7bc99eca9.
Stewart, R., & Ermon, S. (2017, February). Label-free supervision of neural networks with physics and domain knowledge. In Thirty-First AAAI Conference on Artificial Intelligence.
Rajpurkar, Pranav, Hannun, Awni, Masoumeh, Bourn, … Y., A. (2017, July 6). Cardiologist-Level Arrhythmia Detection with Convolutional Neural Networks.
Romero, F. P., Romaguera, L. V., Vázquez-Seisdedos, C. R., Costa, M. G. F., & Neto, J. E. (2018). Baseline wander removal methods for ECG signals: A comparative study. arXiv preprint arXiv:1807.11359.
Kyono, T., Gilbert, F. J., & van der Schaar, M. Multi-view Multi-task Learning for Improving Autonomous Mammogram Diagnosis.
Gender bias. (n.d.). Retrieved from http://wordbias.umiacs.umd.edu/.
Silver, D., Schrittwieser, J., Simonyan, K., Antonoglou, I., Huang, A., Guez, A., … & Chen, Y. (2017). Mastering the game of go without human knowledge. Nature, 550(7676), 354.
Jakobi, N., Husbands, P., & Harvey, I. (1995, June). Noise and the reality gap: The use of simulation in evolutionary robotics. In European Conference on Artificial Life (pp. 704-720). Springer, Berlin, Heidelberg.
Murali, A., Chen, T., Alwala, K. V., Gandhi, D., Pinto, L., Gupta, S., & Gupta, A. (2019). PyRobot: An Open-source Robotics Framework for Research and Benchmarking. arXiv preprint arXiv:1906.08236.